Note
Click here to download the full example code or to run this example in your browser via Binder
A introduction tutorial to fMRI decoding#
Here is a simple tutorial on decoding with nilearn. It reproduces the Haxby 2001 study on a face vs cat discrimination task in a mask of the ventral stream.
J.V. Haxby et al. “Distributed and Overlapping Representations of Faces and Objects in Ventral Temporal Cortex”, Science vol 293 (2001), p 2425.-2430.
This tutorial is meant as an introduction to the various steps of a decoding
analysis using Nilearn meta-estimator: nilearn.decoding.Decoder
It is not a minimalistic example, as it strives to be didactic. It is not meant to be copied to analyze new data: many of the steps are unnecessary.
Retrieve and load the fMRI data from the Haxby study#
First download the data#
The nilearn.datasets.fetch_haxby function will download the
Haxby dataset if not present on the disk, in the nilearn data directory.
It can take a while to download about 310 Mo of data from the Internet.
from nilearn import datasets
# By default 2nd subject will be fetched
haxby_dataset = datasets.fetch_haxby()
# 'func' is a list of filenames: one for each subject
fmri_filename = haxby_dataset.func[0]
# print basic information on the dataset
print('First subject functional nifti images (4D) are at: %s' %
fmri_filename) # 4D data
First subject functional nifti images (4D) are at: /home/alexis/nilearn_data/haxby2001/subj2/bold.nii.gz
Visualizing the fmri volume#
One way to visualize a fmri volume is
using nilearn.plotting.plot_epi.
We will visualize the previously fetched fmri data from Haxby dataset.
Because fmri data are 4D (they consist of many 3D EPI images), we cannot
plot them directly using nilearn.plotting.plot_epi (which accepts
just 3D input). Here we are using nilearn.image.mean_img to
extract a single 3D EPI image from the fmri data.
from nilearn import plotting
from nilearn.image import mean_img
plotting.view_img(mean_img(fmri_filename), threshold=None)
Feature extraction: from fMRI volumes to a data matrix#
These are some really lovely images, but for machine learning
we need matrices to work with the actual data. Fortunately, the
nilearn.decoding.Decoder object we will use later on can
automatically transform Nifti images into matrices.
All we have to do for now is define a mask filename.
A mask of the Ventral Temporal (VT) cortex coming from the Haxby study is available:
mask_filename = haxby_dataset.mask_vt[0]
# Let's visualize it, using the subject's anatomical image as a
# background
plotting.plot_roi(mask_filename, bg_img=haxby_dataset.anat[0],
cmap='Paired')
<nilearn.plotting.displays._slicers.OrthoSlicer object at 0x7ff8ed6110f0>
Load the behavioral labels#
Now that the brain images are converted to a data matrix, we can apply machine-learning to them, for instance to predict the task that the subject was doing. The behavioral labels are stored in a CSV file, separated by spaces.
We use pandas to load them in an array.
import pandas as pd
# Load behavioral information
behavioral = pd.read_csv(haxby_dataset.session_target[0], delimiter=' ')
print(behavioral)
labels chunks
0 rest 0
1 rest 0
2 rest 0
3 rest 0
4 rest 0
... ... ...
1447 rest 11
1448 rest 11
1449 rest 11
1450 rest 11
1451 rest 11
[1452 rows x 2 columns]
The task was a visual-recognition task, and the labels denote the experimental condition: the type of object that was presented to the subject. This is what we are going to try to predict.
conditions = behavioral['labels']
print(conditions)
0 rest
1 rest
2 rest
3 rest
4 rest
...
1447 rest
1448 rest
1449 rest
1450 rest
1451 rest
Name: labels, Length: 1452, dtype: object
Restrict the analysis to cats and faces#
As we can see from the targets above, the experiment contains many conditions. As a consequence, the data is quite big. Not all of this data has an interest to us for decoding, so we will keep only fmri signals corresponding to faces or cats. We create a mask of the samples belonging to the condition; this mask is then applied to the fmri data to restrict the classification to the face vs cat discrimination.
The input data will become much smaller (i.e. fmri signal is shorter):
condition_mask = conditions.isin(['face', 'cat'])
Because the data is in one single large 4D image, we need to use index_img to do the split easily.
from nilearn.image import index_img
fmri_niimgs = index_img(fmri_filename, condition_mask)
We apply the same mask to the targets
conditions = conditions[condition_mask]
# Convert to numpy array
conditions = conditions.values
print(conditions.shape)
(216,)
Decoding with Support Vector Machine#
As a decoder, we use a Support Vector Classifier with a linear kernel. We
first create it using by using nilearn.decoding.Decoder.
from nilearn.decoding import Decoder
decoder = Decoder(estimator='svc', mask=mask_filename, standardize=True)
The decoder object is an object that can be fit (or trained) on data with labels, and then predict labels on data without.
We first fit it on the data
We can then predict the labels from the data
prediction = decoder.predict(fmri_niimgs)
print(prediction)
['face' 'face' 'face' 'face' 'face' 'face' 'face' 'face' 'face' 'cat'
'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'face' 'face' 'face'
'face' 'face' 'face' 'face' 'face' 'face' 'cat' 'cat' 'cat' 'cat' 'cat'
'cat' 'cat' 'cat' 'cat' 'face' 'face' 'face' 'face' 'face' 'face' 'face'
'face' 'face' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat'
'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'face' 'face' 'face'
'face' 'face' 'face' 'face' 'face' 'face' 'face' 'face' 'face' 'face'
'face' 'face' 'face' 'face' 'face' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat'
'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat'
'face' 'face' 'face' 'face' 'face' 'face' 'face' 'face' 'face' 'face'
'face' 'face' 'face' 'face' 'face' 'face' 'face' 'face' 'cat' 'cat' 'cat'
'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'face' 'face' 'face' 'face' 'face'
'face' 'face' 'face' 'face' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat'
'cat' 'cat' 'face' 'face' 'face' 'face' 'face' 'face' 'face' 'face'
'face' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'face'
'face' 'face' 'face' 'face' 'face' 'face' 'face' 'face' 'cat' 'cat' 'cat'
'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat'
'cat' 'cat' 'cat' 'face' 'face' 'face' 'face' 'face' 'face' 'face' 'face'
'face' 'face' 'face' 'face' 'face' 'face' 'face' 'face' 'face' 'face'
'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat' 'cat']
Note that for this classification task both classes contain the same number of samples (the problem is balanced). Then, we can use accuracy to measure the performance of the decoder. This is done by defining accuracy as the scoring. Let’s measure the prediction accuracy:
print((prediction == conditions).sum() / float(len(conditions)))
1.0
This prediction accuracy score is meaningless. Why?
Measuring prediction scores using cross-validation#
The proper way to measure error rates or prediction accuracy is via cross-validation: leaving out some data and testing on it.
Manually leaving out data#
Let’s leave out the 30 last data points during training, and test the prediction on these 30 last points:
fmri_niimgs_train = index_img(fmri_niimgs, slice(0, -30))
fmri_niimgs_test = index_img(fmri_niimgs, slice(-30, None))
conditions_train = conditions[:-30]
conditions_test = conditions[-30:]
decoder = Decoder(estimator='svc', mask=mask_filename, standardize=True)
decoder.fit(fmri_niimgs_train, conditions_train)
prediction = decoder.predict(fmri_niimgs_test)
# The prediction accuracy is calculated on the test data: this is the accuracy
# of our model on examples it hasn't seen to examine how well the model perform
# in general.
print("Prediction Accuracy: {:.3f}".format(
(prediction == conditions_test).sum() / float(len(conditions_test))))
Prediction Accuracy: 0.767
Implementing a KFold loop#
We can manually split the data in train and test set repetitively in a KFold strategy by importing scikit-learn’s object:
from sklearn.model_selection import KFold
cv = KFold(n_splits=5)
# The "cv" object's split method can now accept data and create a
# generator which can yield the splits.
fold = 0
for train, test in cv.split(conditions):
fold += 1
decoder = Decoder(estimator='svc', mask=mask_filename, standardize=True)
decoder.fit(index_img(fmri_niimgs, train), conditions[train])
prediction = decoder.predict(index_img(fmri_niimgs, test))
print(
"CV Fold {:01d} | Prediction Accuracy: {:.3f}".format(
fold,
(prediction == conditions[test]).sum() / float(len(
conditions[test]))))
CV Fold 1 | Prediction Accuracy: 0.886
CV Fold 2 | Prediction Accuracy: 0.767
CV Fold 3 | Prediction Accuracy: 0.767
CV Fold 4 | Prediction Accuracy: 0.698
CV Fold 5 | Prediction Accuracy: 0.744
Cross-validation with the decoder#
The decoder also implements a cross-validation loop by default and returns an array of shape (cross-validation parameters, n_folds). We can use accuracy score to measure its performance by defining accuracy as the scoring parameter.
n_folds = 5
decoder = Decoder(
estimator='svc', mask=mask_filename,
standardize=True, cv=n_folds,
scoring='accuracy'
)
decoder.fit(fmri_niimgs, conditions)
Cross-validation pipeline can also be implemented manually. More details can be found on scikit-learn website.
Then we can check the best performing parameters per fold.
print(decoder.cv_params_['face'])
{'C': [100.0, 100.0, 100.0, 100.0, 100.0]}
Note
We can speed things up to use all the CPUs of our computer with the n_jobs parameter.
The best way to do cross-validation is to respect the structure of the experiment, for instance by leaving out full sessions of acquisition.
The number of the session is stored in the CSV file giving the behavioral data. We have to apply our session mask, to select only cats and faces.
session_label = behavioral['chunks'][condition_mask]
The fMRI data is acquired by sessions, and the noise is autocorrelated in a given session. Hence, it is better to predict across sessions when doing cross-validation. To leave a session out, pass the cross-validator object to the cv parameter of decoder.
from sklearn.model_selection import LeaveOneGroupOut
cv = LeaveOneGroupOut()
decoder = Decoder(estimator='svc', mask=mask_filename, standardize=True,
cv=cv)
decoder.fit(fmri_niimgs, conditions, groups=session_label)
print(decoder.cv_scores_)
{'cat': [1.0, 1.0, 1.0, 1.0, 0.9629629629629629, 0.8518518518518519, 0.9753086419753086, 0.40740740740740744, 0.9876543209876543, 1.0, 0.9259259259259259, 0.8765432098765432], 'face': [1.0, 1.0, 1.0, 1.0, 0.9629629629629629, 0.8518518518518519, 0.9753086419753086, 0.40740740740740744, 0.9876543209876543, 1.0, 0.9259259259259259, 0.8765432098765432]}
Inspecting the model weights#
Finally, it may be useful to inspect and display the model weights.
Turning the weights into a nifti image#
We retrieve the SVC discriminating weights
coef_ = decoder.coef_
print(coef_)
[[-3.88470589e-02 -1.86752449e-02 -3.22276101e-02 -2.88103156e-02
4.17748897e-02 1.10473280e-02 1.69629521e-02 -5.49688684e-02
-1.93773754e-02 -3.50417390e-02 1.08277920e-02 -1.28501685e-02
-1.54318110e-02 -3.78043672e-02 -3.68279622e-02 2.27558027e-02
6.55006537e-03 -7.64041540e-03 1.66731818e-02 -8.00447757e-03
5.28260858e-02 -8.15727821e-02 -6.35571469e-02 2.40757713e-02
4.58824065e-02 -2.22076512e-02 -1.76882392e-02 2.21689962e-02
-9.51052658e-03 5.74704622e-02 2.13813819e-02 -9.12119138e-02
4.02845343e-03 -2.88624637e-02 -3.88124985e-02 -3.34317835e-02
2.20855999e-03 8.71164615e-03 -3.36653188e-02 -2.40700472e-02
-6.80082184e-02 1.65044039e-02 2.70137012e-02 -6.55144233e-03
-1.21380461e-02 5.46412204e-02 8.11546228e-03 3.60126609e-02
-1.52387759e-02 7.01265905e-02 1.28214042e-03 2.07521720e-02
-4.09199127e-03 3.71551894e-02 -3.76545355e-02 -1.03610494e-02
-2.37699942e-02 -5.47603953e-02 4.41999549e-02 -1.47077216e-01
-2.33518027e-02 1.86655424e-02 6.64351579e-02 -9.05548655e-02
-1.21726327e-02 -2.94679161e-03 3.21324454e-02 -3.03308701e-02
6.13949539e-02 1.12014204e-02 1.93355429e-02 -1.30260499e-02
4.41941778e-02 -2.22555998e-02 6.86547381e-02 1.69012892e-02
1.78551990e-02 1.00063908e-02 2.98481844e-02 -2.51578132e-02
1.05947998e-02 -6.30483837e-03 2.21074929e-03 -2.22817921e-02
1.42258582e-02 -1.52785489e-02 -1.97787162e-02 -4.31615104e-02
-4.54074440e-02 3.40811704e-02 -2.78550629e-02 -2.80245056e-02
-3.69302050e-02 -5.70138592e-02 -6.97323205e-02 3.19251110e-03
-8.33539714e-03 -3.36854284e-02 3.03554160e-02 8.66314089e-03
6.17992154e-03 5.92797810e-02 9.05110705e-03 -1.48581493e-02
1.43214556e-02 -1.08762411e-02 2.67057778e-02 4.72688791e-02
-2.95714973e-02 3.08740773e-02 1.57553584e-02 -3.16008258e-02
-3.99190602e-02 -5.38979279e-02 2.81972842e-02 -1.11834993e-02
-5.44117251e-02 6.30730460e-02 -1.49668277e-02 2.47159808e-03
-4.55570353e-02 -1.83423808e-02 1.19705348e-02 -3.71288978e-02
-2.24791327e-03 4.57568401e-02 4.78068926e-02 2.51051364e-03
-4.30721564e-02 -5.33634065e-03 5.75659334e-02 7.39144428e-03
-3.19809470e-02 4.34818873e-03 1.67903974e-02 -2.91880822e-02
-2.23726605e-03 -8.28194318e-03 -9.97890761e-03 2.16655324e-02
-1.92056270e-03 -1.32898405e-02 -2.79642646e-02 -1.74906314e-02
-9.15567240e-03 -7.08042584e-03 -1.42697338e-02 5.05700475e-02
-1.84395833e-02 -4.70413168e-02 1.72190128e-02 -4.75570325e-02
-9.06991113e-04 3.99829091e-02 7.52268240e-02 7.24250985e-03
4.81496658e-02 4.49523498e-02 3.60350854e-02 -8.14553020e-03
1.94961531e-02 3.57077201e-02 4.88177741e-02 3.82079981e-02
6.22477882e-02 6.12261610e-02 -1.68375587e-02 1.66160734e-02
3.34743249e-02 -1.79794200e-02 4.45397355e-02 -3.52424235e-02
-3.66475829e-02 -4.61414163e-03 4.85713460e-02 3.38887355e-02
6.20129163e-03 1.73237530e-02 2.01276059e-02 2.16579674e-02
2.90729906e-02 2.37269602e-02 4.83610628e-02 -9.20490689e-03
-2.81970148e-02 -2.13304679e-02 1.80423908e-03 4.78566332e-02
-9.76561320e-03 1.11160615e-02 -1.64704749e-02 -2.88446661e-02
2.42268823e-02 -1.22079465e-02 -2.92192544e-02 -2.89204464e-02
-3.38760315e-02 -3.64213006e-03 2.64727996e-02 4.57031951e-02
-5.92018812e-02 -2.13147489e-02 -3.08700985e-02 5.48929082e-02
-3.38041763e-02 6.11195832e-03 1.41179056e-02 1.09946235e-02
5.32575594e-02 -2.11837873e-02 6.36001296e-03 -1.12817455e-02
-2.63616678e-02 -2.21909401e-02 -5.30669736e-02 -3.97749592e-02
-1.29431051e-01 -3.27320586e-02 -2.89007953e-02 -9.11539209e-03
-7.26979332e-03 -3.70176331e-02 -6.33423117e-02 2.04171240e-03
-8.24862977e-02 -6.69634286e-02 -2.28585919e-03 -2.32902943e-02
1.77469739e-02 -8.72666415e-02 -2.75717436e-03 -4.37286984e-02
-1.27746178e-02 2.77375006e-02 -4.31669071e-02 -3.21909773e-02
-2.27496719e-02 -2.56846877e-02 2.03153756e-02 -9.88053107e-03
-3.14295746e-02 -1.81003457e-02 -1.11802946e-03 -4.16456054e-02
-6.22038568e-02 2.55645755e-04 -6.72171653e-02 6.52437308e-02
1.06278553e-02 2.21493129e-02 -1.98226068e-02 -1.85109504e-02
4.04760503e-02 -3.02130238e-02 -8.08214813e-02 -7.40776980e-02
-4.92688051e-02 -1.01542409e-02 1.09170290e-02 -4.48197603e-02
2.92093488e-02 7.03555477e-03 5.06284421e-03 -4.82925854e-03
2.48286383e-03 2.99976465e-02 -2.62555364e-03 4.63553492e-03
7.88404617e-02 1.04607153e-02 1.67696751e-02 -4.35721162e-02
-1.08619523e-02 2.09747296e-02 -4.40930102e-02 3.15727089e-03
6.97068278e-02 8.59641329e-02 4.95096609e-02 6.02631474e-03
5.55187032e-02 -2.98207245e-02 4.11966459e-03 -3.21183852e-02
-3.14240189e-02 -5.30018451e-02 2.66640831e-02 3.13670718e-02
6.65661468e-03 -1.28393508e-02 2.19675558e-02 5.67235125e-02
2.25087916e-02 -2.04145382e-02 5.09088101e-03 2.84695791e-02
-1.81223743e-02 -8.46502841e-03 -3.18110625e-02 -1.18214466e-02
-4.09899456e-02 3.11041963e-02 9.61297717e-03 -8.24098812e-03
-3.11479618e-02 8.55848572e-03 -9.67714661e-03 1.32033343e-02
4.05486121e-02 8.21007650e-03 -3.26564906e-02 -4.32642205e-03
-1.75123327e-02 6.87116179e-03 3.44343582e-02 7.01686784e-02
2.16268954e-02 5.30877367e-03 8.15658530e-02 6.38546364e-02
-2.30739162e-03 -1.17254311e-02 1.75482577e-01 3.17385914e-02
-3.15194021e-02 3.33277120e-02 2.22249263e-02 9.99724604e-03
-4.73821204e-02 -2.12285212e-02 -3.97808363e-02 -6.02665748e-02
-4.63979352e-02 1.02756450e-02 -3.05375733e-04 1.80352131e-02
-1.75047950e-02 -8.70568565e-02 1.00429905e-01 4.45207219e-03
7.45124649e-02 -6.11977052e-02 2.81052156e-02 -1.40642391e-02
3.13916000e-02 -1.63458967e-02 3.65699511e-02 -5.14568520e-03
1.44761647e-02 6.34384479e-02 2.34024347e-02 8.79029064e-02
6.13932804e-02 -1.39020678e-02 2.06770473e-02 -3.14570641e-03
5.14253174e-02 -2.88096998e-02 1.59906550e-02 2.09224537e-02
-3.28411599e-02 -2.58825324e-02 -5.59116293e-02 -3.63771195e-02
1.12594518e-02 2.16792846e-02 -1.51321193e-02 -7.81035186e-03
2.42018613e-02 9.44819202e-02 -2.62430409e-02 1.16248523e-04
-5.23291624e-03 4.17020972e-02 8.83631559e-02 6.22078456e-03
1.86170207e-02 1.54274712e-02 3.49548500e-03 6.19254396e-03
-1.19521456e-02 1.59130725e-02 7.10289964e-03 -8.91137657e-02
-3.53333171e-03 1.23197461e-02 3.03211249e-02 -2.36742942e-02
-3.81953895e-02 -4.97580541e-02 4.65828049e-02 -1.23004038e-02
-1.10092593e-02 2.17590464e-02 2.18214525e-02 2.62919368e-02
1.05029812e-02 1.84180466e-02 8.31944682e-04 -6.63468139e-03
3.48613090e-02 1.48988839e-02 -1.11346832e-02 6.67399166e-03
-1.99598497e-02 -3.98119264e-02 3.01187717e-02 -1.09587923e-02
-4.10853879e-02 2.71433910e-02 1.16142931e-02 -1.55126308e-02
3.26914675e-02 3.94583834e-02 8.47091567e-03 2.19425638e-02
-9.86312650e-03 -3.60583513e-02 -4.75927430e-02 1.89646420e-02
-5.57029344e-02 -3.31012941e-02 -2.24390745e-02 -3.35396046e-02
-4.06398428e-02 1.08607188e-02 1.12543440e-02 7.61360843e-02
4.03806085e-03 3.06311491e-02 2.88498791e-02 4.70374361e-03
5.12217666e-02 -4.09447588e-02 1.22996853e-03 -2.49839322e-02
5.84586575e-02 -1.04721991e-01 -4.40681313e-02 1.18251314e-02
-5.81869229e-02 -4.81119563e-02 9.15424894e-03 1.03016988e-02
-5.07926605e-03 -3.22633457e-02 -3.18666044e-02 -1.53435472e-02
-5.19997090e-02 1.55244162e-02 2.92793946e-02 -1.92076892e-02
1.76309703e-02 2.67380077e-02 5.75230989e-02 -1.37856977e-02
2.59815712e-02 1.50062021e-02 1.27146488e-02 -2.28690254e-02
-1.06426250e-02 9.79323512e-03 -4.76401254e-02 1.63868780e-02]]
It’s a numpy array with only one coefficient per voxel:
print(coef_.shape)
(1, 464)
To get the Nifti image of these coefficients, we only need retrieve the coef_img_ in the decoder and select the class
coef_img = decoder.coef_img_['face']
coef_img is now a NiftiImage. We can save the coefficients as a nii.gz file:
decoder.coef_img_['face'].to_filename('haxby_svc_weights.nii.gz')
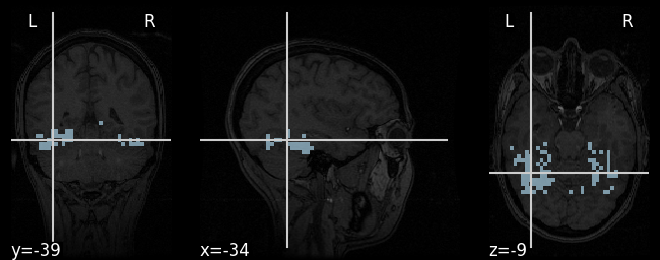
Plotting the SVM weights#
We can plot the weights, using the subject’s anatomical as a background
plotting.view_img(
decoder.coef_img_['face'], bg_img=haxby_dataset.anat[0],
title="SVM weights", dim=-1
)
What is the chance level accuracy?#
Does the model above perform better than chance?
To answer this question, we measure a score at random using simple strategies
that are implemented in the nilearn.decoding.Decoder object. This is
useful to inspect the decoding performance by comparing to a score at chance.
Let’s define a object with Dummy estimator replacing ‘svc’ for classification setting. This object initializes estimator with default dummy strategy.
dummy_decoder = Decoder(estimator='dummy_classifier', mask=mask_filename,
cv=cv)
dummy_decoder.fit(fmri_niimgs, conditions, groups=session_label)
# Now, we can compare these scores by simply taking a mean over folds
print(dummy_decoder.cv_scores_)
{'cat': [0.38888888888888895, 0.38888888888888895, 0.38888888888888895, 0.6111111111111112, 0.38888888888888895, 0.6111111111111112, 0.38888888888888895, 0.38888888888888895, 0.38888888888888895, 0.38888888888888895, 0.6111111111111112, 0.38888888888888895], 'face': [0.38888888888888895, 0.38888888888888895, 0.38888888888888895, 0.6111111111111112, 0.38888888888888895, 0.6111111111111112, 0.38888888888888895, 0.38888888888888895, 0.38888888888888895, 0.38888888888888895, 0.6111111111111112, 0.38888888888888895]}
Further reading#
Decoding with ANOVA + SVM: face vs house in the Haxby dataset For decoding without a precomputed mask
FREM: fast ensembling of regularized models for robust decoding
Total running time of the script: ( 0 minutes 43.174 seconds)
Estimated memory usage: 933 MB